Note: This post is part of a series on developing resmack. See the resmack tag for all posts in the series.
← Part 1 Grammar Fuzzing Thoughts
Part 3 Perf Event Performance Overhead →
I took a small break from working on resmack-rust (renamed to resmack-rust to free up the name resmack) to explore writing a snapshot-based fuzzer.
Often my “fuzzers” focus very heavily on the data generation aspect (see gramfuzz, pfp), with the debugging/fuzz-harness/etc being almost an afterthought.
I won’t be doing the same thing with resmack. Although I am starting with the data generation, my plan is to turn it into a full fuzzer, capable of compiling/launching/instrumenting target programs and performing genetic mutations (mutation/crossover) on the raw data and the grammar states that are saved into the corpus.
With that being said, this post is specifically about the “full” fuzzer experiment and a few lessons I learned.
Resmack Fuzz Test Link to heading
resmack-fuzz-test is a feedback-driven, snapshot-based fuzzer that uses:
- ptrace
- process snapshotting/restoring
- using
/proc/pid/map - using
process_vm_writev
- using
- dynamic memory breakpoints specified by the target process
- attempt at using performance counters as a feedback mechanism
Clone the project with:
git clone https://gitlab.com/d0c-s4vage/resmack-fuzz-test.git
Ptrace Link to heading
resmack-fuzz-test uses ptrace to:
- Debug the target process
- Catch signals
- Capture register values
These are used along with the inline assembly in the contrived target program to signal:
- the pointer to the input data
- the original [max] size of the input data
- the end of meaningful execution
The target process is launched and traced by spawning the new process,
setting PTRACE_TRACEME,
and using waitpid()
to wait for events from the tracee:
let child = unsafe {
println!("Spawning {}", target_bin);
Command::new(target_bin)
.arg("AAAA")
.pre_exec(|| {
ptrace::traceme().expect("Could not trace process");
Ok(())
})
.spawn()
.expect("Could not spawn")
};
let child_pid = Pid::from_raw(child.id() as i32);
...
loop {
match waitpid(child_pid, None) {
Ok(WaitStatus::Exited(_, status)) => ...
Ok(WaitStatus::Stopped(_, Signal::SIGTRAP)) => ...
Ok(WaitStatus::Stopped(pid, signal)) => ...
Ok(WaitStatus::Continued(_)) => ...
Ok(WaitStatus::PtraceEvent(pid, signal, v)) => ...
Ok(WaitStatus::Signaled(pid, signal, val)) => ...
Ok(WaitStatus::StillAlive) => ...
Ok(WaitStatus::PtraceSyscall(pid)) => ...
Err(v) => ...
}
}
Memory Breakpoints Link to heading
Memory (hardware) breakpoints are set and cleared
by setting values on the dr0 debug register and the dr7 debug control
register via PTRACE_POKEUSER ptrace requests:
// load current dr7 value
let debug_reg_off = offset_of!(libc::user, u_debugreg);
let mut debug_ctl_val: u32 = libc::ptrace(
ptrace::Request::PTRACE_PEEKUSER as ptrace::RequestType,
child_pid,
debug_reg_off + (8 * 7),
0,
) as u32;
// modify the dr7 value
...
// save the address to enable the breakpoint on into dr0
let res = libc::ptrace(
ptrace::Request::PTRACE_POKEUSER as ptrace::RequestType,
child_pid,
debug_reg_off,
addr,
);
// set the new dr7 value
let res = libc::ptrace(
ptrace::Request::PTRACE_POKEUSER as ptrace::RequestType,
child_pid,
debug_reg_off + (8 * 7),
debug_ctl_val,
);
Up to four memory breakpoints can be set using this method with registers
dr0 through dr3.
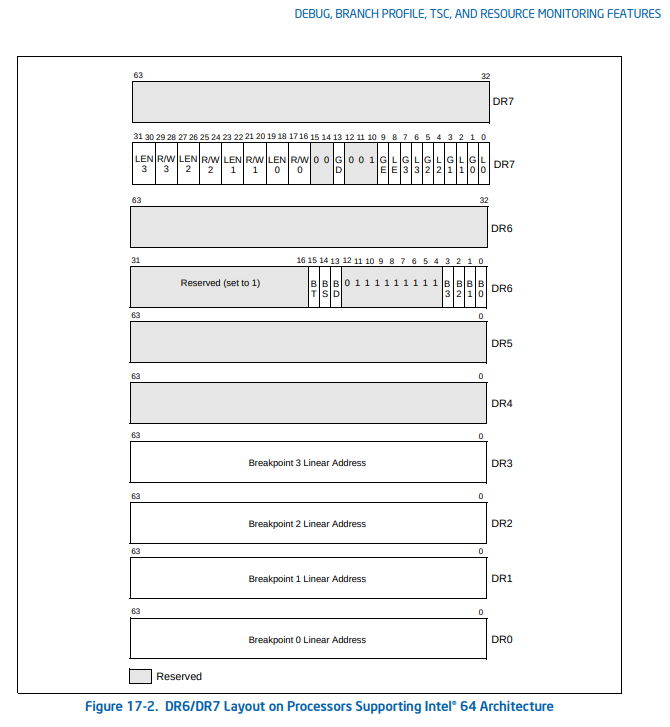
Notes on dr7 Values
Link to heading
Reading the Intel manual on the debug register is highly recommended. A few non-intuitive points that I used from the manual:
the le and ge bits should be set to 1 for exact breakpoint
If these are set, the processor will break on the exact instruction that caused the breakpoint condition.
LE and GE (local and global exact breakpoint enable) flags (bits 8, 9) —
This feature is not supported in the P6 family processors, later IA-32 processors, and Intel 64 processors. When set, these flags cause the processor to detect the exact instruction that caused a data breakpoint condition. For backward and forward compatibility with other Intel processors, we recommend that the LE and GE flags be set to 1 if exact breakpoints are required.
the gd bit should be set to 1 to break before a mov occurs
GD (general detect enable) flag (bit 13) —
Enables (when set) debugregister protection, which causes a debug exception to be generated prior to any MOV instruction that accesses a debug register. When such a condition is detected, the BD flag in debug status register DR6 is set prior to generating the exception. This condition is provided to support in-circuit emulators. When the emulator needs to access the debug registers, emulator software can set the GD flag to prevent interference from the program currently executing on the processor. The processor clears the GD flag upon entering to the debug exception handler, to allow the handler access to the debug registers.
the 10th bit should always be set to 1
Notice the 10th (reserved) bit is hard-coded to 1:
Contrived Target Link to heading
In target.c, two blocks of inline assembly exist.
The first inline assembly block
sets the rax register to argv[1], and the
rbx register to strlen(argv[1]), and then triggers a breakpoint (int3):
asm("mov $0xf00dfeed, %%rcx;"
"mov %0, %%rax;"
"mov %1, %%rbx;"
"int3;"
"xor %%rcx, %%rcx;"
:
: "r" (argv[1]), "r" (strlen(argv[1]))
: "rcx", "rbx", "rax"
);
When this breakpoint is handled by the fuzzer, the pointer (rax) and size
(rbx) of the input data are extracted from the target. A memory breakpoint is
then set on the input pointer. 0xf00dfeed in rcx is used to indicate that the
breakpoint is the one that contains the pointer and size in rax and rbx:
if regs.rcx == 0xf00dfeed {
log_debug!("Received tagged memory address");
log_debug!("| bp addr: {:x}", regs.rax);
log_debug!("| max_mem_len: {}", regs.rbx);
log_debug!("| rip: {:x}", regs.rip);
_overwrite_data_addr = Some(regs.rax);
_overwrite_data_max_len = Some(regs.rbx as usize);
// has to be on a word boundary (can't be an odd number)
set_watchpoint(child_pid, regs.rax & !1, WatchpointSize::Two, false);
}
Once the memory breakpoint is hit, a snapshot is taken of all writable pages in the target, as well as the current register state. See the snapshotting section.
At this point, fuzzing iterations begin (see the Mutation and Feedback and Corpus sections), with registers and modified pages being restored, and with the input data being overwritten by new, random data.
The target process then continues until the final, manual breakpoint is hit:
asm("mov $0xfeedf00d, %%rcx;"
"int3;"
"xor %%rcx, %%rcx;"
:
:
: "%rcx"
);
at which point the process snapshot is restored and the next iteration continues.
Slow Target “Prelude” Link to heading
The target was intentionally made to have a slow “prelude” before getting to the actual code that should be fuzzed:
char buf1[0x10000];
char buf2[0x10000];
PRINT("Long prelude");
for (int i = 0; i < 0x10000; i++) {
memcpy(buf1, buf2, sizeof(buf1));
}
PRINT("Done with long prelude");
Using the memory breakpoint to wait until the target data is actually used allows us to skip over this expensive section of code before taking the snapshot. Not skipping over this results in ~2300x fewer iterations per second.
Feedback and Corpus Link to heading
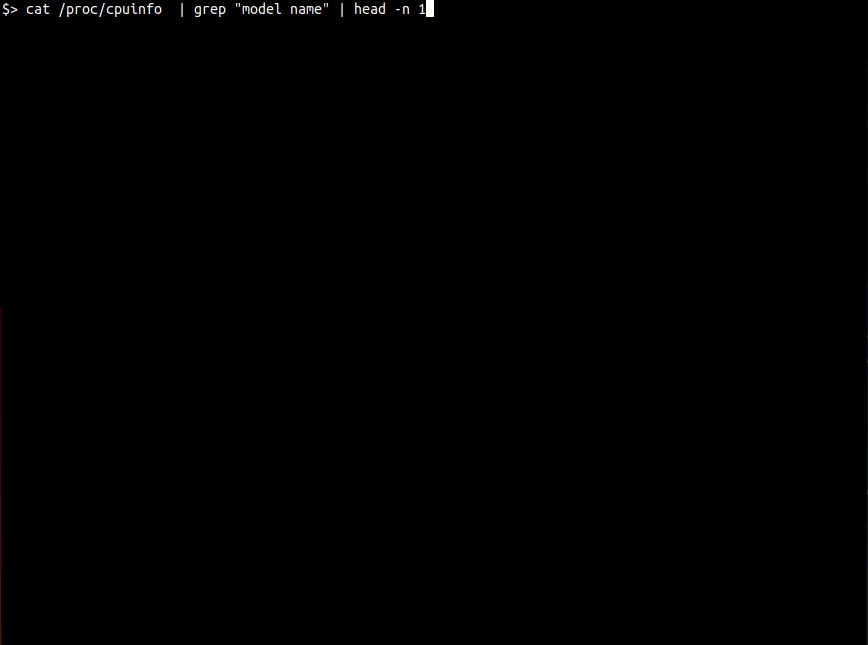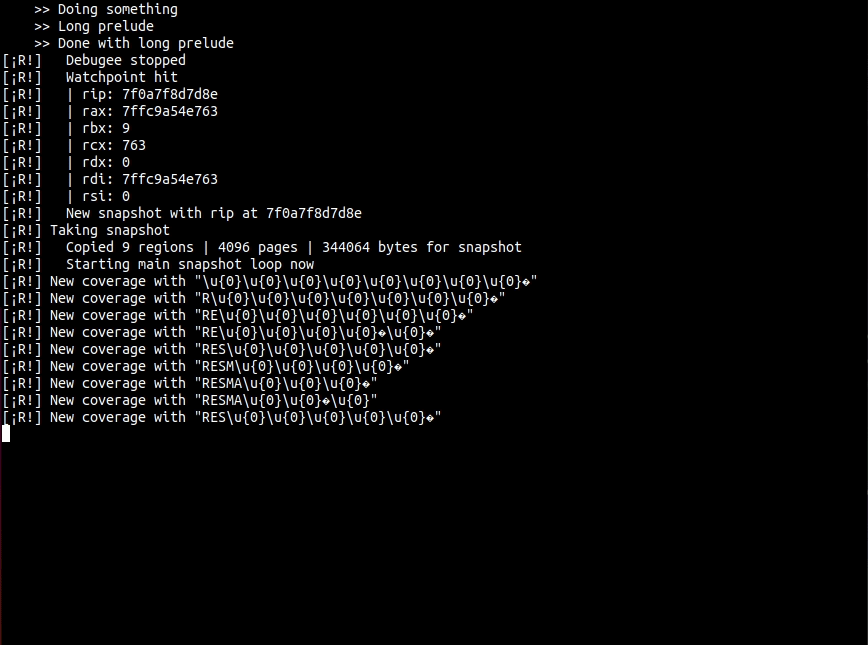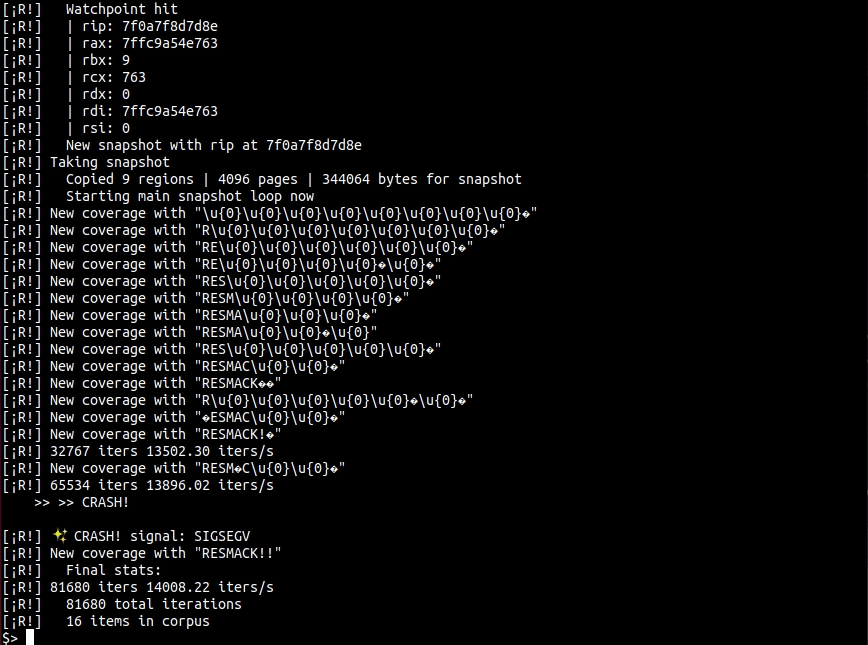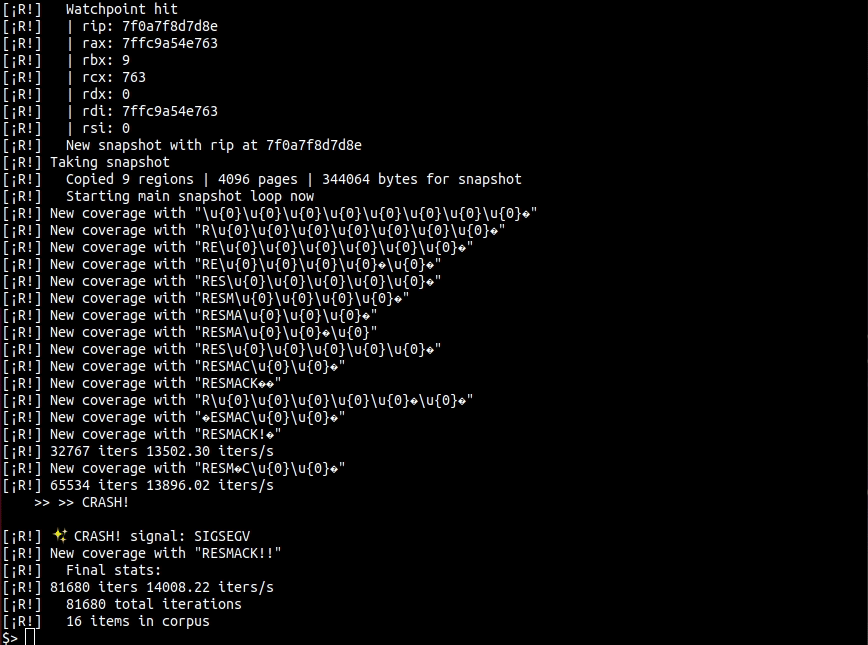
resmack-fuzz-test uses perf events for its feedback metric. Unique pairs of branch count and instruction count are used to identify unique paths through the target program during fuzzing. Below is the output of resmack-fuzz-test with the addition of printing the coverage stats for each new input discovered:
[¡R!] New coverage with "\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 22, branches: 8 }
[¡R!] New coverage with "R\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 27, branches: 9 }
[¡R!] New coverage with "RE\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 32, branches: 10 }
[¡R!] New coverage with "�\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 23, branches: 9 }
[¡R!] New coverage with "RES\u{0}\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 37, branches: 11 }
[¡R!] New coverage with "RESM\u{0}\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 42, branches: 12 }
[¡R!] New coverage with "R\u{0}\u{0}\u{0}\u{0}\u{2}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 28, branches: 10 }
[¡R!] New coverage with "RESMA\u{0}\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 47, branches: 13 }
[¡R!] New coverage with "RESM\u{0}\u{0}\u{0}(�"
[¡R!] CoverageStats { cycles: 0, instrs: 43, branches: 13 }
[¡R!] New coverage with "RESMAC�\u{0}\u{0}"
[¡R!] CoverageStats { cycles: 0, instrs: 52, branches: 14 }
[¡R!] New coverage with "RESMA\'\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 48, branches: 14 }
[¡R!] New coverage with "RE\u{0}\u{0}\u{0}�\u{0}\u{0}�"
[¡R!] CoverageStats { cycles: 0, instrs: 33, branches: 11 }
[¡R!] 32767 iters 14777.54 iters/s
[¡R!] 65534 iters 14905.92 iters/s
[¡R!] New coverage with "RESMACKԓ"
[¡R!] CoverageStats { cycles: 0, instrs: 57, branches: 15 }
[¡R!] New coverage with "RESMAC�8Q"
[¡R!] CoverageStats { cycles: 0, instrs: 53, branches: 15 }
[¡R!] New coverage with "RESMACK!�"
[¡R!] CoverageStats { cycles: 0, instrs: 62, branches: 16 }
>> >> CRASH!
[¡R!] ✨ CRASH! signal: SIGSEGV
[¡R!] New coverage with "RESMACK!!"
[¡R!] CoverageStats { cycles: 0, instrs: 1060, branches: 231 }
Inputs are saved into an in-memory corpus if they cause new code paths to be explored (have a unique branch + instruction count pair) within the target.
One of the interesting aspects of using performance metrics as a feedback mechanism is that performance metrics are non-deterministic. The performance numbers are sample-based. For example, see this blogpost on easyperf.net about tips for trying to make performance counters more deterministic.
Although performance counters are non-deterministic, the branch and instruction
count pairs have a usable range of variance in their values. If the variance
in the counter values was too high, every input would be seen as having
caused a unique codepath to be explored. This is exactly what occurs when
the cycle count metric is used as a feedback value. With the cycle count
performance counter tracked along with the branch and instruction count,
successful runs of resmack-fuzz-test had a total of ~2000 items in its corpus
whereas using only the branch and instruction count has less than 20.
UPDATE 2020-07-21: See Part 3: Perf Event Performance Overhead for a quick benchmark on the overhead of using perf events.
Corpus Item Weights Link to heading
The in-memory corpus uses a simple weighting system that doubles the odds of being chosen of the most recent half of its values:
pub fn get_item(&self, rand: &mut Rand) -> Option<&Item> {
let len = self.items.len();
if len == 0 {
return None;
}
let rand_idx = if len > 4 {
let half_size = len / 2;
let first_half = len - half_size;
// double the odds of the last half
let new_size = len + half_size;
let tmp = rand.next() as usize % new_size;
if tmp < first_half {
tmp
} else {
first_half + (tmp - first_half) / 2
}
} else {
rand.next() as usize % len
};
self.items.get(rand_idx)
}
Although I haven’t benchmarked this, doubling the odds of being chosen of the most recent half seemed to work better than doing the same for the most recent quarter of items in the corpus. It would be interesting to see empirical data for this.
Mutation Link to heading
The mutations performed in resmack-fuzz-test are basic mutations that either mutate the data in-place, or insert a random number of bytes:
pub fn mutate(rand: &mut Rand, data: &mut Vec<u8>, max_len: usize) {
if data.len() == 0 {
mut_insert_rand(rand, data, max_len);
return;
}
let idx = rand.next();
match idx % 2 {
0 => mut_insert_rand(rand, data, max_len),
1 => mut_change_rand(rand, data),
_ => panic!("Math is broken"),
};
}
To minimize the number of rand() calls, each byte in the u64 random
value is used when choosing the random offset, random number of bytes, and
random values to insert:
// 5 bytes to choose random indices
// 1 bytes to num bytes to insert % 5
// 2 bytes to choose insert index
let rand_num: u64 = rand.next();
let rand_num_bytes: usize = (rand_num & 0xff) as usize;
let rand_byte_data = (rand_num >> 8) & 0xffffffffff;
let rand_offset = ((rand_num >> 48) & 0xffff) as usize;
This could be taken further to only call rand() once in mutate(), use one
bit to choose which mutation type to use, and then use the remaining bits
in the mut_change_rand() and mut_insert_rand() functions.
Process Snapshotting Link to heading
Process snapshot taking and restoring makes use of a few features of procfs to capture and restore process state:
/proc/pid/map/proc/pid/clear_refs/proc/pid/pagemapprocess_vm_writev
As the code was forming and moving around during development, I didn’t have a clear picture about which method is fastest. I ended up benchmarking most combinations of methods that I could think of to make the decision easier. The benchmark results are in the Benchmarks of Snapshot Restoration Methods section.
Snapshotting in this project is done by:
- Identifying all writeable regions in target process’ memory
- Saving all:
- Writeable regions
- Register Values (both normal registers and floating point)
- <doing work>
- Restoring [changed?] target process state and registers
Determining Writeable Regions with /proc/pid/maps
Link to heading
/proc/pid/maps shows information about the mapped regions of the processes memory.
E.g.:
$> cat /proc/self/maps
56548d283000-56548d285000 r--p 00000000 fd:01 36700321 /usr/bin/cat
56548d285000-56548d28a000 r-xp 00002000 fd:01 36700321 /usr/bin/cat
56548d28a000-56548d28d000 r--p 00007000 fd:01 36700321 /usr/bin/cat
56548d28d000-56548d28e000 r--p 00009000 fd:01 36700321 /usr/bin/cat
56548d28e000-56548d28f000 rw-p 0000a000 fd:01 36700321 /usr/bin/cat
56548ebaa000-56548ebcb000 rw-p 00000000 00:00 0 [heap]
7fa2d267c000-7fa2d269e000 rw-p 00000000 00:00 0
7fa2d269e000-7fa2d2c0e000 r--p 00000000 fd:01 36704859 /usr/lib/locale/locale-archive
7fa2d2c0e000-7fa2d2c33000 r--p 00000000 fd:01 36703856 /usr/lib/x86_64-linux-gnu/libc-2.30.so
7fa2d2c33000-7fa2d2dab000 r-xp 00025000 fd:01 36703856 /usr/lib/x86_64-linux-gnu/libc-2.30.so
7fa2d2dab000-7fa2d2df5000 r--p 0019d000 fd:01 36703856 /usr/lib/x86_64-linux-gnu/libc-2.30.so
7fa2d2df5000-7fa2d2df8000 r--p 001e6000 fd:01 36703856 /usr/lib/x86_64-linux-gnu/libc-2.30.so
7fa2d2df8000-7fa2d2dfb000 rw-p 001e9000 fd:01 36703856 /usr/lib/x86_64-linux-gnu/libc-2.30.so
7fa2d2dfb000-7fa2d2e01000 rw-p 00000000 00:00 0
7fa2d2e19000-7fa2d2e1a000 r--p 00000000 fd:01 36703852 /usr/lib/x86_64-linux-gnu/ld-2.30.so
7fa2d2e1a000-7fa2d2e3c000 r-xp 00001000 fd:01 36703852 /usr/lib/x86_64-linux-gnu/ld-2.30.so
7fa2d2e3c000-7fa2d2e44000 r--p 00023000 fd:01 36703852 /usr/lib/x86_64-linux-gnu/ld-2.30.so
7fa2d2e45000-7fa2d2e46000 r--p 0002b000 fd:01 36703852 /usr/lib/x86_64-linux-gnu/ld-2.30.so
7fa2d2e46000-7fa2d2e47000 rw-p 0002c000 fd:01 36703852 /usr/lib/x86_64-linux-gnu/ld-2.30.so
7fa2d2e47000-7fa2d2e48000 rw-p 00000000 00:00 0
7ffea9bee000-7ffea9c10000 rw-p 00000000 00:00 0 [stack]
7ffea9cc6000-7ffea9cc9000 r--p 00000000 00:00 0 [vvar]
7ffea9cc9000-7ffea9cca000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
Similar to normal file system permissions, the writable regions of the target
process’ memory are indicated with -w--.
Copying the data at specific ranges can be done by reading seeking to the
desired address and reading directly from /proc/pid/mem or by using
process_vm_readv.
For the purposes of resmack-fuzz-test, the process of capturing the original state of all writeable regions is only done once and does not have a critical impact on the fuzzer’s performance.
Finding Dirty Pages With /proc/pid/clear_refs and /proc/pid/pagemap
Link to heading
Thanks to the Checkpoint/Restore In Userspace (CRIU) Project, a way exists to find which pages of a process have been modified since a certain time. Knowing which pages are dirty can greatly improve performance by only restoring pages that were actually modified.
Writing 4 to the file /proc/pid/clear_refs will clear all soft-dirty bits
on the target process. From the
procfs man page:
4 (since Linux 3.11)
Clear the soft-dirty bit for all the pages associated with the process. This is used (in conjunction with /proc/[pid]/pagemap) by the check-point restore system to discover which pages of a process have been dirtied since the file /proc/[pid]/clear_refs was written to.
The status of the soft-dirty bit of each page in the process can be checked
using the /proc/pid/pagemap file. This file contains a 64-bit integer for
every virtual page within the process, with bit 55 (the soft-dirty bit)
being set indicating that the Page Table Entry (PTE) has been modified:
63 If set, the page is present in RAM.
62 If set, the page is in swap space
61 (since Linux 3.5) The page is a file-mapped page or a shared anonymous page.
60–57 (since Linux 3.11) Zero
56 (since Linux 4.2) The page is exclusively mapped.
55 (since Linux 3.11) PTE is soft-dirty (see the kernel source file Documen‐ tation/admin-guide/mm/soft-dirty.rst).
54–0 If the page is present in RAM (bit 63), then these bits provide the page frame number, which can be used to index /proc/kpageflags and /proc/kpagecount. If the page is present in swap (bit 62), then bits 4–0 give the swap type, and bits 54–5 encode the swap offset.
Before Linux 3.11, bits 60–55 were used to encode the base-2 log of the page size.
To employ
/proc/pid/pagemapefficiently, use/proc/pid/mapsto determine which areas of memory are actu‐ ally mapped and seek to skip over unmapped regions.
See the referenced kernel source file Documentation/admin-guide/mm/soft-dirty.rst for additional details.
Benchmarks of Snapshot Restoration Methods Link to heading
After running perf on resmack-fuzz-test, it became apparent that the process snapshotting was the main bottleneck of the fuzzer:
cargo build # yes, debug so we get symbols
perf record --call-graph=dwarf -g target/debug/ptrace_test $(pwd)/a.out AAAAAAAAA
perf report
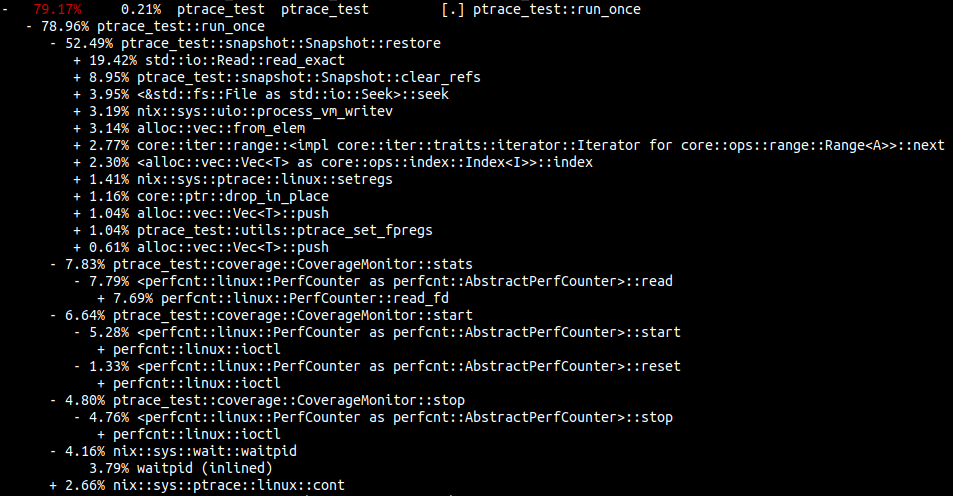
Notice how
19.42%of the time is spent instd::io::Read::read_exactreading in the values from the pagemap8.95%of the time is spent writing the character4to/proc/pid/clear_refs3.95%of the time is spent seeking with<&std::fs::File as std::io::Seek>::seek- Using perf events for coverage adds
19%overhead (combine the start/stop/stats percentages)
It’s pretty crazy how much time is spent dealing with procfs and coverage.
I ended up experimenting with different snapshot restoration methods to try to reduce the snapshotting bottleneck. These were combinations of choosing the data ranges to restore and how to restore them:
- What to copy
- Restore all region data range at once
- Restore all region data in page size (
4096) chunks - Restore dirty individual pages
- How to copy
- Direct seeks/writes to
/proc/pid/mem - Using
process_vm_writev
- Direct seeks/writes to
- Best/Worst Case
- Sparse - One page per memory region
- Dense - Every page per memory region
The line graph below shows the benchmarks of combinations of the above values. The benchmark was created with the command:
cargo bench --bench snapshots -- --verbose
The x-axis is the number of pages that need to be restored.

View the full snapshot_restore benchmarks for additional details/insights.
Using procfs with clear_refs and pagemap to determine dirty pages and
updating the target process via process_vm_writev is the fastest. The bottom
dark green line is the best-case (dense) scenario for this method, and the
purple line is the worst-case (sparse) for this method.
Future Improvements Link to heading
Below are a few things that should improve snapshotting performance and that would be fun to explore:
task_diag
This is an effort to speed up procfs. See Andrei Vagin’s blog post How fast is Procfs and his linux kernel fork with task_diag implemented.
MVAs (Multiple Virtual Address Spaces)
The paper Fast in-memory CRIU for docker containers discusses how kernel support for MVAs can reduce snapshot restoration times:
This accelerates the snapshot/restore of address spaces by two orders of magnitude, resulting in an overall reduction in snapshot time by up to 10× and restore time by up to 9×
Emulation
The utility of Brandon Falk’s chocolate milk became more apparent as I looked into the bottlenecks surrounding snapshot taking and restoration. Having an emulator that is specifically designed to keep track of dirty pages, take snapshots, and restore them would drastically improve the process and give greater flexiblity in what can be accomplished in userland.
Kernel Extension
A custom kernel extension to take and restore snapshots of processes with a single context switch could have a large impact on the snapshotting process. I haven’t found any existing works on this (I’m sure they exist though). It would be fun to test this out myself and see what happens.