Note: This post is part of a series on developing resmack. See the resmack tag for all posts in the series.
← Part 4 Grammar Mutations Part 6 Stateful & Dynamic Grammars →
Grammar Recursion Link to heading
Before we dive into this topic, let’s do a quick refresher on one method of controlling grammar recursion. I’ve blogged previously about how grammar recursion can be dealt with by preprocessing the rules so that every rule knows its “shortest exit path”.
Since few will actually click the link above and read the full post, let’s do a small example.
Recursion Recap Link to heading
Suppose we have the grammar below:
item1: hello | <item2>
item2: <item3>
item3: world | , <item1>
We could preprocess each rule, item1 and item2, so that each knows its
shortest path to resolution.
| Rule | Notes | Path________ |
|---|---|---|
item1 |
choose hello |
 |
item2 |
No choice, choose item3 |
 |
item3 |
choose world |
 |
At generation time, the current recursion level could be tracked and compared with a specified maximum recursion level. If the maximum recursion level is met, then each generated rule could be told to choose one of the precomputed shortest paths (yes, multiple options might qualify as the shortest) instead of a random path.
This keeps the generated data valid‡, while still keeping recursion limits in check.
‡The simple approach is to bail entirely and start outputting empty strings (or something similar) once the recursion limit has been hit. This may, however start producing invalid data
Controlling Recursion II Link to heading
In my previous blog post we discussed managing and mutating a grammar-based corpus. What if we wanted to not only change subtrees of the data, but directly impact the recursion levels of each of the rules?
To put this in another light, it’s useful to think about how maximum recursion might usually be set in a grammar-based data generator. Often (anecdotally always), this is determined up-front by the user:

Or more technically:
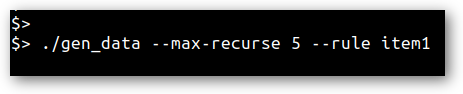
This is the opposite of what a fuzzer’s intention is, especially a feedback-driven fuzzer. Feedback-driven fuzzers are supposed to figure out these settings for you based on feedback!
Fuzzing Maximum Recursion Link to heading
In my previous post, I showed a snippet of the corpus metadata with ellipses in a few places:
Corpus Metadata:
...
num_entries: 1
entry[0]:
... < < < CORPUS ITEM METADATA
item_header:
num_states: 16
state[ 0]: ... rule_idx: 0 "run_on_sentence" rand_state: ebe8df8d|fa44b3ba|6be3539c|f28d3079
state[ 1]: ... rule_idx: 1 "sentence" rand_state: e3215c4e|7a4f3fab|096cf811|4c1e1846
state[ 2]: ... rule_idx: 3 "subject" rand_state: e3215c4e|7a4f3fab|096cf811|4c1e1846
^
^
^
RULE STATE HEADER
Originally I started storing the maximum recursion level used to generate
a given corpus item in the CORPUS ITEM METADATA ellipses section. Storing
this value with each corpus item was absolutely required. Without this
information being persisted it would be impossible
to correctly replay anything. That is, unless the user specified the exact
same maximum recursion value as was used in the original generation.
The major downside to storing the maximum recursion level at a “global” level for each corpus item is that you can’t modify it. You might as well generate new inputs from scratch and not have a corpus if you change the maximum recursion level.
On the other hand, storing the maximum recursion level within each
RULE STATE HEADER allows us to increase/decrease the maximum recursion levels
on a per-rule basis at mutation time:
Corpus Metadata:
...
entry[17]:
...
item_header:
num_states: 24
state[ 0]: max_depth: 5 rule_idx: 6 rand_state: b8b3d092|1d3d34e3|88b39e4d|b11ec30a
state[ 1]: max_depth: 8 rule_idx: 5 rand_state: 8bafc0c3|20104eb8|761adc9b|d4fa3131
state[ 2]: max_depth: 8 rule_idx: 4 rand_state: 8bafc0c3|20104eb8|761adc9b|d4fa3131
state[ 3]: max_depth: 8 rule_idx: 3 rand_state: 7d03e17d|63e93116|25813be8|0d7b27c2
state[ 4]: max_depth: 8 rule_idx: 2 rand_state: f11ca20d|7fc881f2|e8c81312|c8ea3c72
state[ 5]: max_depth: 8 rule_idx: 0 rand_state: 4d3e33ba|994842ae|80e84ee3|7e08890d
state[ 6]: max_depth: 8 rule_idx: 1 rand_state: 179b1f82|4e9ab6cb|dccbc5b8|c7c4383d
state[ 7]: max_depth: 8 rule_idx: 2 rand_state: 1c91f339|6bb3c034|29b2444b|fecf014a
state[ 8]: max_depth: 4 rule_idx: 0 rand_state: 5dc15dd8|81c78a31|e73fd1b9|1a6b855f
state[ 9]: max_depth: 8 rule_idx: 1 rand_state: 89ed3247|5e907746|52a3df72|e60bf4ab
state[10]: max_depth: 8 rule_idx: 2 rand_state: b1f7bfd8|ce1f85aa|bc06bc98|803aba34
state[11]: max_depth: 8 rule_idx: 0 rand_state: b1f7bfd8|ce1f85aa|bc06bc98|803aba34
state[12]: max_depth: 8 rule_idx: 1 rand_state: c110c33b|24da1269|f3492143|58e9a9d1
state[13]: max_depth: 1 rule_idx: 2 rand_state: 78ab72dd|c6e83521|9c4d7c08|78d4f523
state[14]: max_depth: 1 rule_idx: 0 rand_state: 78ab72dd|c6e83521|9c4d7c08|78d4f523
...
Practical Example Link to heading
Let’s create a simple test program to fuzz to demonstrate the usefulness of fuzzing the maximum recursion level:
#include <stdlib.h>
#include <string>
#include <sstream>
#include <vector>
#include <iostream>
extern "C" int LLVMFuzzerTestOneInput(const char* raw_data, size_t data_size) {
std::string data(raw_data, data_size);
std::vector<std::string> parts;
std::istringstream iss(data);
std::string item;
while (std::getline(iss, item, ' ')) {
parts.push_back(item);
}
// answer: "just drink more* coffee"
size_t i = 0;
if (parts.size()-1 <= i || parts[i++] != "just") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "drink") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "more") { return 0; }
if (parts.size()-1 <= i || parts[i++] != "coffee") { return 0; }
((void(*)())0)();
return 0;
}
The program above is simple enough: it crashes by calling 0 if provided the
data:
just drink more more more more more more more more more more more more coffee
Below is a simple grammar that we’ll benchmark and test:
// ~BNF grammar
sentence: <word> " " <word> " " <word-list> " " <word>
word: just | drink | more | coffee
word-list: <word> [<word-list-opt>]
word-list-opt: " " <word-list>
// resmack implementation
rules
->AddRule("sentence", AND_S(" ",
REF("word"), REF("word"), REF("word-list"), REF("word")
))
->AddRule("word", OR("just", "drink", "more", "coffee"))
->AddRule("word-list", AND(REF("word"), REF("word-list-opt")))
->AddRule("word-list-opt", OPT(AND(V(" "), REF("word-list"))))
Experiment Results Link to heading
Below are the results of running resmack with and without mutating the per-rule maximum recursion:
- 100 times with:
- maximum depth of 30
- stopping at either:
- first crash
- 10,000,000 iterations
| Without Max Recursion Fuzzing | With Max Recursion Fuzzing |
|---|---|
 |
 |
| 13/100 crashed | 100/100 crashed |
| 87/100 no crash | 0/100 no crash |
| avg iters for crashed: 3148800 | avg iters for crashed: 7796 |
Note that although the maximum depth is set to 30, in the case where the recursion level is fuzzed, any value between 0 and 30 will be used as a new maximum recursion value for each saved PRNG rule state.
Being able to individually fuzz per-rule maximum recusion values has a massive benefit.
Warning: Too Much Sugar is Unhealthy Link to heading
Syntactic sugar helps make expressing complex constructs simpler. In resmack, I’ve added a few constructs to resmack to make expressing optional [sub]rules easier.
For example, instead of defining multiple options for word-list as shown
below:
rules
->AddRule("word", OR("just", "drink", "more", "coffee"))
->AddRule("word-list", REF("word"))
->AddRule("word-list", AND(REF("word"), V(" "), REF("word-list")))
I added an OPT item that makes it possible to define the grammar like so:
rules
->AddRule("word", OR("just", "drink", "more", "coffee"))
->AddRule("word-list", AND(
REF("word"),
OPT(AND(
V(" "), REF("word-list")
))
))
This works great, and makes it easier (for me) to tell what the intention of the rule is.
However, since resmack only saves the PRNG state when each rule is
generated, the embedded OPT value is never exposed as a directly mutatable
element. This also means that directly fuzzing the maximum recursion level
of recursive definitions that use embedded OPT values is not possible.
Lesson: Expose the optional portion of recursive rules as distinct top-level rules:
rules
->AddRule("word", OR("just", "drink", "more", "coffee"))
->AddRule("word-list", AND(REF("word"), REF("word-list-opt")))
->AddRule("word-list-opt", OPT(AND(V(" "), REF("word"), REF("word-list-opt"))));
Remarks Link to heading
I feel there is still a better way to directly mutate/control the amount of recursion in recursive list definitions. I am hesitant to add list-specific constructs into resmack though - it feels like I’d be starting to hack in features to handle specific use cases on top of something that I’ve tried very hard to keep as generic and flexible as possible.
My next blog post will cover related topics of keeping things generic and not coding towards specific use cases.